ASCII, 아스키 코드
ASCII(American Standard Code for Information Interchange): 미국 정보 교환 표준 부호
컴퓨터나 통신 장비 등에서 텍스트를 표현하려는 목적으로 만들어진 표준이다. 이 표준에 따르면 문자와 1Byte를 1:1 맵핑시킨 표를 만들 수 있다. 이것이 우리가 흔히 말하는 아스키 코드표다.
아스키 코드는 이름에서 알 수 있듯 American Standard이므로 공통적으로 쓰는 구두점이나 숫자를 빼면 영문자만 매핑되어 있다. 따라서 아스키 코드를 사용한다면, 영어권 이외의 국가에서는 자국의 문자를 표시할 수 없다. 자국 문자의 출력을 위해 아스키와 같은 코드를 따로 만들어 사용할 수도 있지만, 그렇게 되면 아스키 코드와 호환이 되지 않으므로 서로간의 데이터 전송에 문제가 발생할 것이다.
따라서 영문 이외의 다른 문자를 추가하기 위한 많은 표준들이 이후에 만들어졌다. 그런 표준들은 모두(내가 아는 한) 아스키 코드와의 호환성을 고려하는 것에서부터 시작했다. 예를 들어 ISO-8859-1의 경우에는, 아스키 코드에서 사용하지 않는 MSB 비트를 사용하여 새로운 문자 공간 128개를 추가하여 기존 호환성을 맞추었고, UTF-8은 가변 길이로 인코딩하면서, 아스키 코드 이외의 글자에 대해서만 2바이트 이상을 사용하는 것으로 호환성을 맞추었다.
1960년대에 만들어지면서 개정도 되고 여러 이력을 가진 채로 지금까지 사용중인데, 자세한 년도나 히스토리는 위키피디아의 ASCII를 찾아보자.
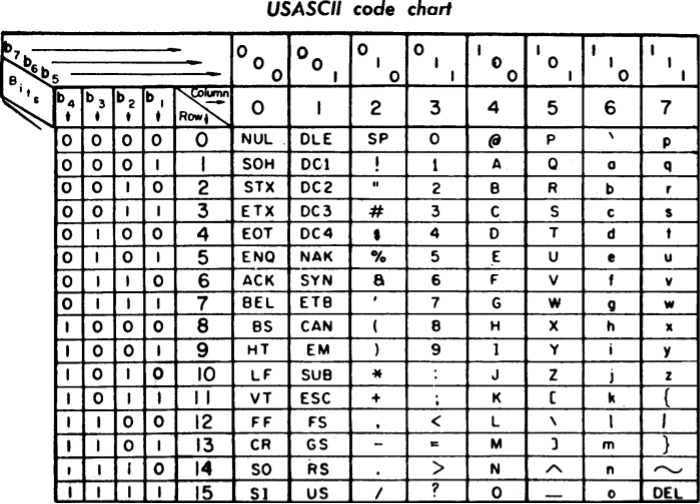
출처: https://ko.wikipedia.org/wiki/ASCII#/media/File:USASCII_code_chart.png
{kind=link}
아스키 코드 정보
여기서는 아스키 코드로 알 수 있는 정보를 적어 보자.
제어 코드
범위는 0x00부터 0x1F까지, 그리고 0x7F를 사용한다.
제어 코드는 출력되지 않는 문자를 말한다. 출력되지 않지만 문자열을 수식하거나 그 자체로 특별한 기능을 처리한다. 이 제어 코드는 OS마다 다른 기능을 수행하기도 하고, 옛날에는 기능이 있었지만 지금은 아무런 기능을 하지 않는 경우도 있다. 예를 들어 리눅스에서는 \n, Newline 문자는 줄을 바꿔주는 역할을 하지만, Windows에서는 \r\n이 이를 처리한다.(그래서 리눅스에서의 파일이 윈도우에서 열면 줄바꿈이 제대로 되지 않는 경우가 있다.)
배치의 순서
아스키 코드의 배치는 다음과 같다.
- 모든 대문자는 소문자보다 먼저 등장한다. 즉 Z는 a보다 먼저 출현한다.
- 숫자와 구두점(punctuation)은 문자보다 먼저 출현한다.
이런 일련의 순서를 ASCIIbetical order라고 부른다.
숫자
범위는 0x30부터 0을 매핑하고 순서대로 나아가서 0x39까지다. 비트로 보면 0x30은 00110000인데, 이는 00110000과 아스키 코드를 비트 연산했을 때의 결과가 바로 그 값이라는 뜻이다. 물론 결과가 9이하, 즉 00001001 이하일 때만 가능한 이야기지만.
영문자
대문자의 범위는 0x41부터 A를 매핑하고 순서대로 나아가서 0x5A까지다. 소문자는 0x61부터 a를 매핑하고 순서대로 나아가서 0x7A까지다. 즉 영문자와 대문자는 각각 0x20의 간격을 가진다. 0x20은 비트 표현으로 00100000인데, 즉 XOR을 통해 영문자와 대문자를 변경할 수 있다는 뜻이다.
#include <stdio.h>
void main() {
int c;
char a, A;
c = 0x20;
a = 'a';
A = 'A';
printf("a to A: %c, %c\n", a, a ^ c);
printf("A to a: %c, %c\n", A, A ^ c);
}
결과는 다음과 같다.
$ ./a.out
a to A: a, A
A to a: A, a